Simcha van Helvoort
De toeslagenaffaire zal voor altijd een zwarte bladzijde zijn in de Nederlandse innovatiegeschiedenis. Algoritmes bij rechtbanken of sollicitatieprocedures die een discriminerend1 karakter hadden waren geen onbekend verhaal. Het verschil: Dit gebeurden vaak in een land als de Verenigde Staten waar de wetgeving over dit soort kwesties minder streng is.
In deze blog wordt niet op de politieke fouten ingegaan. Het feit dat de Nederlandse staat hier een fout heeft gemaakt stellen we niet ter discussie, maar de focus ligt op hoe dit effect heeft op toekomstige algoritmes2 die door zowel de overheid als private bedrijven worden gebruikt. Waarom worden algoritmes eigenlijk gebruikt? Hoe komt het dat een algoritme kan discrimineren? Hoe kan dit herkend worden?

Bron: Mystic Mabel. Flickr.
De hierboven genoemde toeslagenaffaire maakte gebruik van discriminerende risicomodellen3. Dit brengt algoritmes misschien wel slecht in beeld, maar desondanks zullen algoritmes gebruikt blijven worden.
Het voordeel van een Machine Learning algoritme is dat er uit veel verschillende componenten een patroon gevonden kan worden om iets te voorspellen. Dit doen ze niet alleen nauwkeuriger, maar ook sneller en meer consequent. Dit betekent dat complexe vraagstukken relatief makkelijk opgelost kunnen worden met Machine Learning, mits de juiste data beschikbaar is.
Juist daar zit de kern van het probleem: Data. In deze blog wordt het verder uitgelegd, maar ik verklap alvast de conclusie. Uit de data kan blijken dat, bijvoorbeeld bij de toeslagenaffaire, mensen met een tweede nationaliteit in verhouding meer fraude plegen, maar dit betekent niet dat mensen met een tweede nationaliteit daadwerkelijk meer fraude plegen. De één is een observatie en de ander een conclusie, en gek genoeg kunnen die twee aardig wat verschillen.
Het is misschien niet intuïtief om te denken dat iets objectiefs als data het probleem kan zijn voor discriminatie. Vaak is data een observatie of een waarneming, wat per definitie een feit is. Op individueel niveau zal dit ook waar zijn, maar wanneer er naar het grotere plaatje gekeken wordt zullen die feiten wat fluïde worden. De onderstaande afbeelding zal hier meer duidelijkheid over geven.
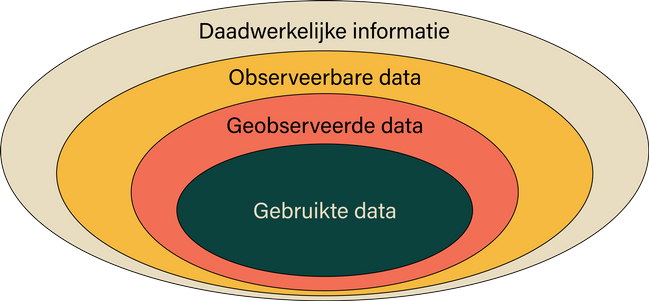
Deze diagram geeft verschillende niveaus van informatie weer. De alomvattende laag is de daadwerkelijke informatie en kleinste laag is de daadwerkelijk gebruikte data. Hieronder wordt verder ingegaan op elke laag.
Gebruikte data: Dit is de data die gebruikt is om een algoritme te maken of om bepaalde grafieken te maken. Op de gebruikte data worden de conclusies getrokken.
Geobserveerde data: Dit is de data die verzameld is. Data in de meest ruwe vorm.
Observeerbare data: Dit is de data dat gemeten kan worden. Vaak wordt maar een klein deel van de mogelijk observeerbare data geobserveerd. Er wordt dan gewerkt met steekproeven waardoor maar een klein deel van de populatie gemeten wordt in de hoop dat het representatief is. Naast steekproeven vallen hier ook kenmerken onder die in sommige gevallen verboden zijn om op te slaan, zoals etnische achtergrond.
Daadwerkelijke informatie: Dit is de waarheid. Een perfecte representatie van de wereld. Veel aspecten hiervan kunnen ook niet in cijfers uitgedrukt worden en zijn daarom lastig te verwerken in een spreadsheet.
Stel je bent benieuwd naar de mening van burgers over het gebruik van hondenparken in jouw gemeente. Je stelt een enquête op om hierachter te komen.
Net als zelflerende algoritmes baseren mensen hun keuzes op de gebruikte data. Voor zowel mensen als algoritmes zijn er veel ‘denkfouten’ die kunnen ontstaan als je met de gebruikte data iets wil zeggen over de daadwerkelijke informatie. Bij mensen noemen we die denkfouten vaak cognitieve biases.
Een vaak voorkomende bias is de ‘observer bias’. Het resultaat van deze bias is dat de observeerder alleen maar dingen observeert die de hij of zij verwacht of wil zien. Wanneer iets buiten het verwachtingspatroon van de observeerder valt, dan zal de observeerder dat negeren of op een verkeerde manier interpreteren.
Stel, de observeerder is in dit geval iemand die toeslagenfraude moet gaan opsporen. In het verleden heeft hij of zij aanvaring gehad met een paar Bulgaren die misbruik hebben gemaakt van het toeslagenstelsel. De observeerder zal dossiers van mensen met Bulgaarse achtergrond hierdoor waarschijnlijk iets nauwer in de gaten moeten houden. Oftewel, niet alle dossiers (geobserveerde data), maar een selectie van de dossiers worden gebruikt (gebruikte data).
Het gevolg van de observer bias is een soort selffulfilling prophecy (zelfvervullende voorspelling). Doordat de observeerder vaker in dossiers kijkt van mensen met een Bulgaarse achtergrond dan bij mensen zonder, zal de observeerder ook meer fraudeurs vinden bij deze groep. Alleen door vervolgens de conclusie te trekken dat Bulgaren vaker frauderen is niet eerlijk. Ze zijn namelijk niet op dezelfde manier behandeld.
Van de onderzochte mensen (gebruikte data) zullen in verhouding meer Bulgaren zitten dan dat er Bulgaren in de gehele populatie zitten. Doordat de observeerder vooringenomen of bevooroordeeld was, is de data dat nu ook.
Net als bij mensen baseren zelflerende algoritmes de keuze op de gebruikte data. Het algoritme beschouwd de data als de harde waarheid en begint daar patronen in te zoeken. Algoritmes houden vaak geen rekening met het verzamelen van data of in hoeverre deze data verschilt met de geobserveerde data of observeerbare data.
Alle data die het algoritme heeft gezien IS de waarheid en de complete waarheid. Geef je een algoritme dus biased data, dan krijg je biased uitkomsten.
Om de bovenstaande reden worden er discriminerende uitspraken gedaan door een algoritme. Dit komt door de data, maar ook door het menselijke aspect (of eerder het gebrek aan). Een algoritme zegt namelijk niet: ‘Mensen met deze kenmerken zijn een fraudeur. Daar valt niet over te betwisten.’ Integendeel, een algoritme beweert eerder: ‘Mensen met deze kenmerken zijn 80% zeker een fraudeur’. De maker van het model (een mens) bepaalt waar de grens ligt om iemand een fraudeur te noemen. Die kan bij 50%, 99% en alle getallen daartussenin liggen. Wat vervolgens gebeurt met deze uitspraak is weer aan de ontwerper.
Een algoritme kijkt namelijk alleen tussen de verschillen van fraudeurs en niet fraudeurs en berekent op basis daarvan wat de kans is dat die persoon een fraudeur is. Dit werkt over het algemeen heel goed in een tal van domeinen:
Beeldherkenningsalgoritmes. Stel je wil uit een afbeelding raden welk dier op de afbeelding staat. Dan zou het algoritme zo kunnen werken: Heeft het object op deze foto een lange nek? Ja? Dan is het een giraf.
In tegenstelling tot discriminatie gaat dit wel over relevante variabelen zonder gevoelig karakter.
In het ideale geval zou een niet relevante variabel ook geen toevoeging hebben voor het algoritme, maar zoals we hiervoor al hebben gezien is dat niet altijd het geval. De basisvoorwaarde is dan ook: Neem geen gevoelige en niet-relevante variabelen mee in je algoritme. Zo weet je in ieder geval dat het discriminatieve algoritme niet discriminatief is op de gevoelige variabel.
Als we dan niet geen gebruik meer maken van gevoelige variabele, is het probleem van discriminerende algoritmes dan opgelost? Het antwoord is helaas: nee, zo makkelijk is het niet.
Laten we een voorbeeld nemen: Migranten zijn over het algemeen minder hoog opgeleid zijn vanwege de Nederlandse-taal-barrière. Stel dat een algoritme het risico dat iemand een fraudeur is bepaalt op basis van opleidingsniveau. Een algoritme zou op die manier vooringenomen kunnen zijn. Niet doordat het algoritme direct vooringenomen is op migratieachtergrond, maar door de associatie met opleidingsniveau.
Dit noemen we indirecte discriminatie. Vanwege een samenhang tussen opleiding en migratieachtergrond wordt er gediscrimineerd in het nadeel van migranten. Dit maakt het probleem lastig, want een ethisch bewust data-scienceteam kan zo toch onbedoeld een discriminerend algoritme maken.
Vanwege de problemen die hierboven zijn beschreven is het belangrijk om achteraf kritisch het algoritme te beoordelen, ondanks het gebruik van een discriminerende variabel of niet. Zo zou een projectteam kunnen kijken naar de Groepsgelijkheid (Group Fairness).
De groepsgelijkheid betekent dat een groep mensen gemiddeld gezien niet anders beoordeeld mag worden dan andere groepen. Als we dit in context plaatsen van een fraude-algoritme, dan zou de groepsgelijkheid het volgende stellen: De groepen van de gevoelige variabel (man/vrouw, migrant/geen migrant etc.) hebben evenveel kans om als fraudeur gezien te worden door het algoritme. Dit wil zeggen dat onder de groep mannen het percentage fraudeurs even hoog is als bij de groep vrouwen.
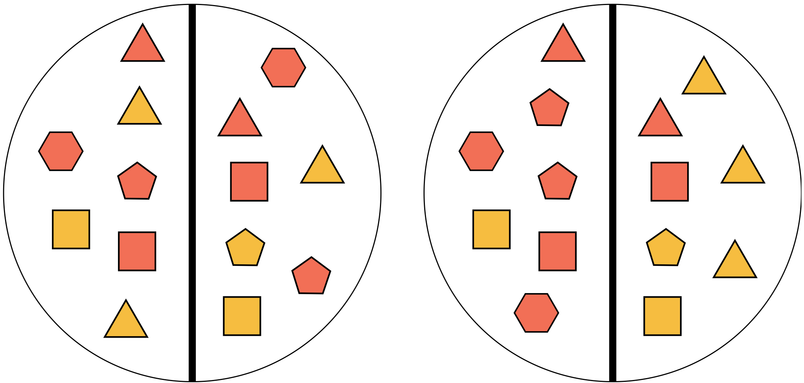
Figuren met meer hoeken moeten aan de linker helft van de cirkel staan. De kleur van de figuren zijn een gevoelig variabel. Welke cirkel is het eerlijkst verdeeld? De cirkel links is volgens de groepsgelijkheid goed, maar de crikel rechts heeft meer figuren met meer hoeken in de linker helft.
Helaas komen hier andere problemen bij kijken. Omdat je per groep vergelijkt verlies je veel informatie. Binnen een groep zit namelijk veel variatie en die negeer je. Zo heeft de groep mannen bijvoorbeeld meer topfunctionarissen met enorme salarissen en vermogens. Zij zullen meer gemotiveerd zijn om belasting te ontwijken. Deze mannen zullen voordeel krijgen als de kans op fraudeur gelijk is bij zowel mannen als vrouwen. Daarom is het beter om te kijken naar Individuele-gelijkheid (Individual Fairness).
Met individuele-gelijkheid wordt gekeken of een individu op dezelfde manier behandeld is als iemand met veel overeenkomsten. Dit leunt op het fundament: Gelijke mensen moeten op een gelijke manier behandeld worden.
Als een man en een vrouw dezelfde opleiding, interesses en ervaring hebben, dan moeten die bij een sollicitatieprocedure evenveel kans hebben op een baan. Deze twee personen lijken veel op elkaar, behalve op de gevoelige variabel (M/V). Als een algoritme hen zou beoordelen wie het meest geschikt is voor een baan, dan zou die uitkomst hetzelfde moeten zijn.
Zo zullen meerdere mensen in een dataset veel overeenkomsten hebben die je kan matchen. Als het algoritme mensen binnen de matches gemiddeld anders beoordeeld, dan kan de eerlijkheid van het algoritme in twijfel gebracht worden. Het nadeel is dat er niet voor elk individu een perfecte kopie op de gevoelige variabel na is waarmee je diegene kan vergelijken. Daardoor zullen sommige matches wat meer gelijkenissen hebben dan andere matches. Bij grotere verschillen binnen de matches is het moeilijker te concluderen of de twee personen gelijk zijn behandeld.
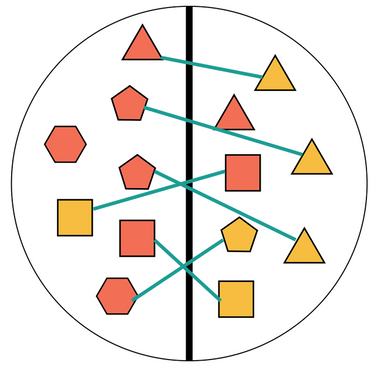
Een aantal figuren zijn gematched. Er kan onderzocht worden of deze figuren op dezelfde manier behandeld zijn. Het nadeel is dat sommige matches niet perfect zijn. Zo zijn twee vijfhoeken gematched met twee driehoeken.
De laatste methode is de Tegenfeitelijke-gelijkheid (Counterfactual Fairness). De tegenfeitelijke-uitkomst betekent: wat was de uitkomst geweest als de feiten anders waren? Stel dat een topfunctionaris van ING niet een man was geweest, maar een vrouw. Is de kans dat deze persoon een fraudeur is volgens het algoritme hetzelfde?
Het mooie aan de tegenfeitelijke-gelijkheid is dat dit de knoop kan doorhakken of een algoritme discriminerend is of niet. Dit stelt namelijk: als exact deze persoon niet [man/vrouw, donker/licht, jong/oud] was geweest, maar het tegenovergestelde, verandert dit de uitkomst? Als gemiddeld gezien de uitkomst anders was geweest, dan is het algoritme discriminerend.

Wat als de zeshoek de andere kleur was geweest? Zou die hetzelfde behandeld worden, of juist niet?
Het lastige van de bovengenoemde gelijkheden is de eis dat de gevoelige variabelen bekend zijn in de dataset. Een dataset zonder gevoelige variabel kan doormiddel van indirecte discriminatie een discriminerende algoritme maken. Daarentegen is het onmogelijk om zonder een gevoelige variabel diezelfde discriminatie te herkennen.
Variabelen zoals geslacht, religie en etnische achtergrond zijn beschermd door de AVG. Deze mogen niet gebruikt worden tenzij er een hele goede reden is. Nu is het voorkomen van discriminatie in een algoritme een legitieme reden om die variabelen te gebruiken, maar het kan zijn dat mensen zelf daar geen toestemming voor geven, en dat recht hebben ze.
Hierdoor kan het gebruik van gevoelige variabelen heel conflicterend voelen. Gevoelige variabelen moeten absoluut niet meegenomen worden in het maken van het algoritme om discriminatie te voorkomen, maar ze zijn wel nodig om te voorkomen dat het algoritme discriminerend is. Dit betekent dat we extreem terughoudend moeten zijn met het gebruik van deze variabelen. Enkel als een algoritme wordt ontwikkeld dat mogelijk discriminerend kan zijn, dan zou je over de gevoelige variabelen van individuen willen beschikken.
Ideaal gezien zouden niet-relevante variabelen ook niet relevant zijn voor het algoritme. Het algoritme zou geen verschil kunnen vinden op basis van die variabelen. Helaas geldt dit niet wanneer de data vooringenomen is. Zelfs zonder de niet-relevante variabelen kan de vooringenomenheid zicht uiten door indirecte discriminatie. Zo zou zelfs een data-scienceteam met aandacht voor ethiek toch een discriminerend algoritme kunnen maken.
Wel zijn er verschillende methodes om erachter te komen of een algoritme discriminerend is of niet. Groepsgelijkheid is relatief simpel, maar is misschien iets te simpel met andere negatieve gevolgen. Individuele-gelijkheid stelt dat gelijke mensen gelijk behandeld moeten worden, maar dit brengt weer technische problemen met zich mee. Alleen met tegenfeitelijke-gelijkheid kunnen we met zekerheid zeggen of een algoritme discriminerend is of niet. Het nadeel van al deze methodes is de noodzakelijkheid van de gevoelige variabel. Zonder informatie over het kenmerk waarop mogelijk gediscrimineerd wordt kan er ook geen discriminatie vastgesteld worden.
Tau Omega adviseert om altijd aandacht te geven aan de eerlijkheid van het algoritme als deze gemaakt is op basis van persoonsgegevens. Ben je en/of werk je samen met een data-scientist stuur dan deze blog door? Daarnaast zou je altijd contact met ons kunnen opnemen voor externe hulp en inzichten. Op deze manier kunnen we het probleem van oneerlijke algoritmes aanpakken. Iets wat drastisch nodig is.
1 In deze blog gebruiken we de volgende definitie van discriminatie: het anders behandelen en beoordelen van een persoon op basis van niet relevante kenmerken en variabelen. Vaak is deze niet relevante variabel ook een gevoelige variabel zoals etnische achtergrond, geslacht of religie.
2 Algoritmes zijn een groep van wiskundige berekeningen in een bepaalde volgorde om een gewenste uitkomst te krijgen. De term Kunstmatige Intelligentie (of Artificial Intelligence (AI)) en Machine Learning is hier nauw aan verbonden. Als we het in deze blog over discriminerende algoritmes hebben zullen we aannemen dat deze zijn ontwikkeld met machine learning
3 Algoritmes of modellen die vaststellen hoe groot het risico is dat iemand een fraudeur is bijvoorbeeld
Rijnstraat 3A - 5215 EA 's-Hertogenbosch
Copyright © Tau Omega
Design door Studio Waaghals


